
Don’t just look at the benchmark figures when you evaluate your language model. A subjective judgement can also lead to interesting insights.
Training or fine-tuning language models and chasing the best F1 on classification tasks has become no less competitive than the F1 people usually associate with car racing. While benchmarks are no doubt informative, useful and have had a tremendous contribution to the advancement of NLP, we believe they are not, and should not, be an end in themselves.
One reason is that language models with worse benchmark scores can still excel on data which has less noisy distribution than the benchmark. In the previous article we also pointed out that training and inference times can matter as much as accuracy.
In this post we would like to take a break from the usual fixation on model scores and share some of the qualitative insights we got into ULMFiT.
Fun fact #1. Domain adaptation and morphological patterns
As part of the Autonomous Voice Assistant (AVA) project for Polish, our purpose was to build a neural language model that can perform well on the e-commerce domain. This is different from the general language you would encounter e.g. on Wikipedia. It’s not just about the lexicon, but also syntax – for instance product descriptions in many online shops tend to be very concise in comparison with the kind of language you see in general corpora.
A typical workflow is to pre-train a general language model e.g. on Wikipedia, fine-tune it on a corpus of product descriptions, and finally calculate perplexity (or pseudo-log perplexity for masked LMs such as BERT). This is a metric that – roughly speaking – tells you how “surprised” or “perplexed” a model is when it sees a sequence of tokens. A perplexity score of 100 means that for each sequence such as “My favorite color is ____” the model has to choose on average between 100 lexically and grammatically plausible words to complete it.
Researchers are often satisfied when they see a low perplexity score and proceed straight to using the model on downstream tasks. However, we wanted to carry out sanity checks on how our models predict the next words and whether fine-tuning them on a corpus of product descriptions carries any promise of improved fits to future tasks. We got some very interesting sentence completions – have a look:
| Sentence Beginning | Most likely sentence completion | |
|---|---|---|
| (general LM) | (finetuned LM) | |
| W 2000 roku uzyskał (In 2000 he obtained) | stopień doktora nauk (a doctorate) | program 3-letniej (a 3-year program) |
| W związku z budową (As a result of building) | nowego kościoła (a new church) | budowy ścian i (building walls and) |
| Drużyna Stanów Zjednoczonych zdobyła złoty medal na (The US national team won gold medal) | mistrzostwach świata w (in the world championship in) | jednym naład[owaniu] (on a single charge) |
| profesjonalna szlifierka idealna do (professional grinder ideal) | końca życia (for the rest of life) | cięcia drewna (for wood cutting) |
Even though the completions are not always very plausible, it is easy to see the effects of domain adaptation. Text fragments sampled from the fine tuned LM are clearly similar to the kind of language you would expect to see in product descriptions in a hardware store (which the finetuning corpus indeed contained in large numbers), rather than in an encyclopedia (as in the general LM).
Not only does a language model store lexical information, but it also encodes morphosyntactic patterns. Fine-tuning to a target domain allows us to capture such patterns in that domain. Compare the following sentences in Polish and their English glosses:
| But | wykonany | z | materiału ___ | → syntetycznego |
|---|---|---|---|---|
| Shoe | Made | Of | Material ___ | → Synthetic |
| (n, sg, genitive case) | (adj, sg case agreement) | |||
| But | wykonany | z | materiałów ___ | → syntetycznych |
| Shoe | Made | Of | Materials ___ | → Synthetic |
| (n, pl, genitive case) | (adj, pl case agreement) |
This effect of fine-tuning may be less directly important in morphologically simple languages such as English. However, languages with a complex case system rely heavily on it to mark subject-verb agreement, agreement between a phrase head and its dependents, or even to directly assign thematic roles (e.g. instrumental case and the instrument role). Correct modelling of such dependencies is important for downstream tasks such as relation extraction where spans contribute as much information as individual token values.
Fun fact #2. Ambiguity in the text = ambiguity in the model
Even though we haven’t submitted our Polish models to the KLEJ benchmark (yet), we ran them on some of the benchmark’s tasks. We observed something very interesting on the sentiment classification task (PolEmo-IN), which has four labels: positive, negative, somewhat in between (“ambiguous”) and zero (=not a review). Our results for the validation dataset look like this:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| __label__meta_zero | 0.99 | 0.92 | 0.96 | 127 |
| __label__meta_plus_m | 0.87 | 0.80 | 0.83 | 209 |
| __label__meta_minus_m | 0.83 | 0.88 | 0.85 | 271 |
| __label__meta_amb | 0.52 | 0.58 | 0.55 | 116 |
| accuracy | 0.81 | 723 | ||
| macro avg | 0.81 | 0.79 | 0.80 | 723 |
| weighted avg | 0.82 | 0.81 | 0.82 | 723 |
It turns out that our classifier built on top of a general ULMFiT language model returned very high confidence scores (y_probs in the tables below) for the categories with clear sentiment.
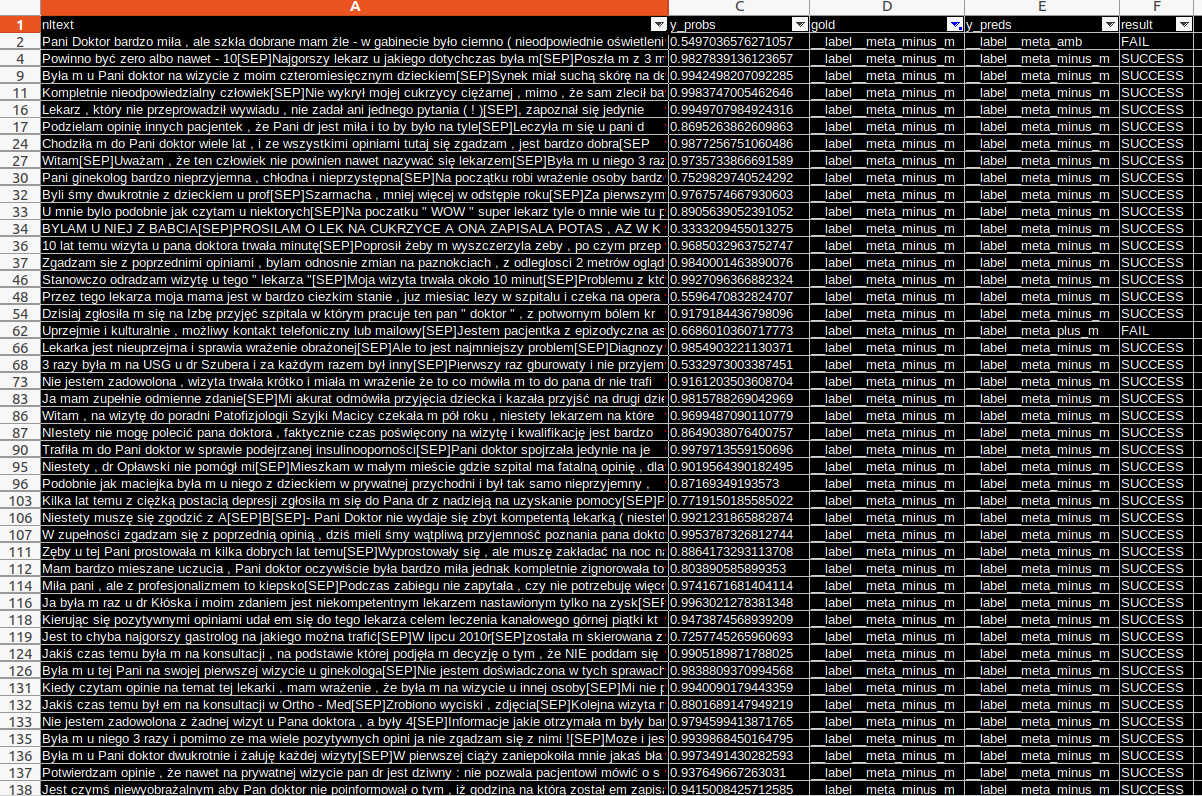
However, where the sentiment was less clear-cut, the predictions for the “ambiguous” class gave consistently lower scores and were visibly more often incorrect:
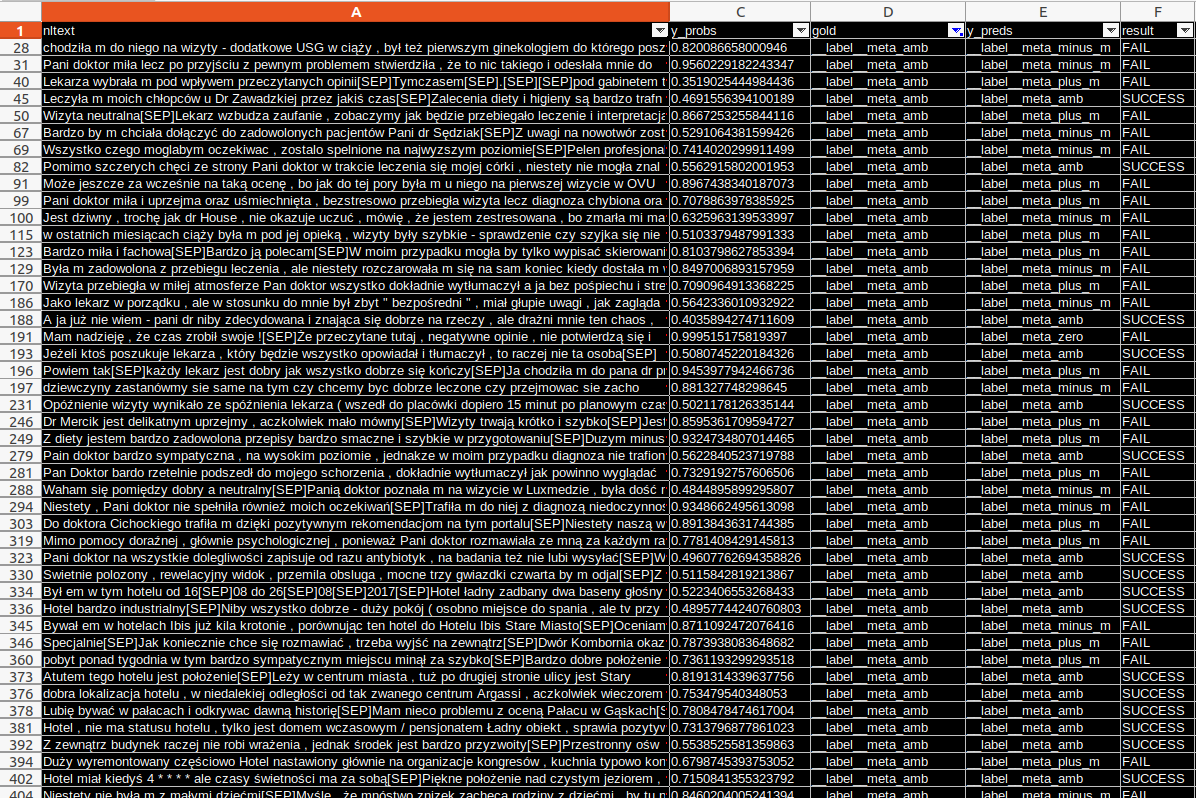
This handling of ambiguous documents appears to be a drawback of recurrent language models. We have seen in our research that whereas RNNs are strong on identifying clear-cut boundaries such as “positive vs negative” or “in-domain vs out-of-domain”, they consistently underperform if the dataset has classes such as “in between”, “ambiguous” or “other”. If you also run into this issue with your data, some options worth considering are:
- adopt a threshold – any class prediction with a score lower than some arbitrarily chosen value (e.g. 0.8) is assigned to the “ambiguous” class
- use label smoothing (this is our speculation, we haven’t tried it) – rather than map each class to a one-hot vector you may mark the “positive” and “negative” classes as more certain than the “ambiguous” class during training:
| Class | One-hot label | With label smoothing |
|---|---|---|
| positive | [0, 1, 0, 0] | [0, 0.8, 0, 0] (or even [0.1, 0.8, 0.05, 0.05]) |
| negative | [0, 0, 1, 0] | [0, 0, 0.9, 0] |
| ambiguous | [0, 0, 0, 1] | [0, 0, 0, 0.6] |
| out-of-domain | [0, 0, 0, 0] | [0, 0, 0, 0] |
If the “ambiguous” class obtains consistently weaker predictions, it might make sense to set its labels closer to 0.5 than 1. The network will then pick up patterns where loss function is substantial (pos / neg / ood) and learn less from examples with a smaller loss (amb). This will not make the ambiguous class distinct from others after softmaxing at inference, but should spread the probability mass to these other classes more evenly than with one-hot encoding. This, in turn, should make the classification by threshold (see previous point) more reliable.
- remodel the task as regression – instead of assigning categorical values you may opt to change the labels to real values. For instance, a positive review can get a score of 10, a negative review a score of 0, ambiguous cases something in between and out-of-domain texts get scores below 0. You will also need to change the cost function from cross-entropy loss to mean squared error or mean absolute error.
Fun fact #3. Sequence tagging also works with ULMFiT
In sequence tagging your objective is to label each token as either belonging to one of the predefined classes or not. Named entity recognition (NER) is an example of a sequence tagging problem where you need to decide which words in a sentence are, for instance, people or company names:
Bill Gates is the founder of Microsoft
where the words “Bill” and “Gates” would be labelled as “person”, and “Microsoft” would be labelled as “organization”.
There are many tutorials on the web on how to use an LSTM network for part-of-speech tagging or named entity recognition. However, we haven’t been able to find any code that uses ULMFiT for that purpose. This is probably because the authors of the original paper and its implementation in FastAI address only LM pretraining, fine tuning and text classification, and do not mention other tasks such as POS-tagging, NER or encoder-decoder setups. Which is a pity, because we really think that with all the advanced regularization techniques this model is capable of much more than document classification. At edrone we needed to train taggers that mark product features in their textual descriptions, so we decided to give ULMFiT a try and write a tagger on top of our Tensorflow port of the encoder. Our initial results are quite encouraging:
Write a sentence to tag: Jaką prędkość obrotową ma ta pilarka?
(What is the rotational speed of this chainsaw?)
<s> O
▁Jak O
ą O
▁prędkość B-N
▁obrot I-N
ową I-N
▁ma O
▁ta O
▁pil O
arka O
? O
</s> OIf you’d like to replicate our experiments with sequence tagging, there is an example script in our repo which shows you how to do it easily with Keras and our pretrained models.

Hubert Karbowy
NLP engineer. Degree in computer science and linguistics. Focused on language modelling and dialog systems. Formerly NLP engineer at Samsung and contributed to Bixby’s development.