
Table of contents
- Step 1 – SQS Queues
- Step 2 – Lambda
- Lambda 1 – initializeExport
- Lambda 2 – checkIfExportIsDone
- Step 3 – CloudWatch Event Rules
- Step 4 – Handle this export in Backend (Java)
- Removing the table (Athena)
- Creating a table (Athena)
- Getting the data
- Step 5 – Delete records from DynamoDB
- Important information
- Summary
- edrone is constantly hiring! Check who we are looking for right now. If it’s you, do not hesitate and apply to our team!
In our company, some time ago we started receiving alarms about exceeding the quota for one of the tables in Amazon DynamoDB. This caused alerts in other parts of the system as the table is used by many different processes.
After a short investigation, we found out that the problem was caused by one of our workers who removed data from this table when the customer of eCommerce we are integrated with requested its right for being forgotten. Removal was not the problem – it was quick.
However, before we proceeded to deleting data, we had to first scan () on the entire table to find out both the partition_key and the secondary index. Due to the fact that the table is a dozen or so GB in size, this scan took a very long time and also consumed many credits from the provisioned read capacity.

We didn’t want to switch from provisioned output to on-demand for this one problem. The costs then skyrocketed enormously.
Looking for a solution to this problem, we implemented batch processing of delete requests (maximum 25 records deleted in one batch). However, as I mentioned earlier, deletion was not a problem – a dead end.
Elsewhere in our system, we often use the option to export tables and / or RDS databases to S3 and then search them with Athena. It turned out that DynamoDB has also been able to use this method for some time. After implementation, we stopped burning our credits:

I got to work. The following describes the steps that had to be taken to make everything fit together nicely.
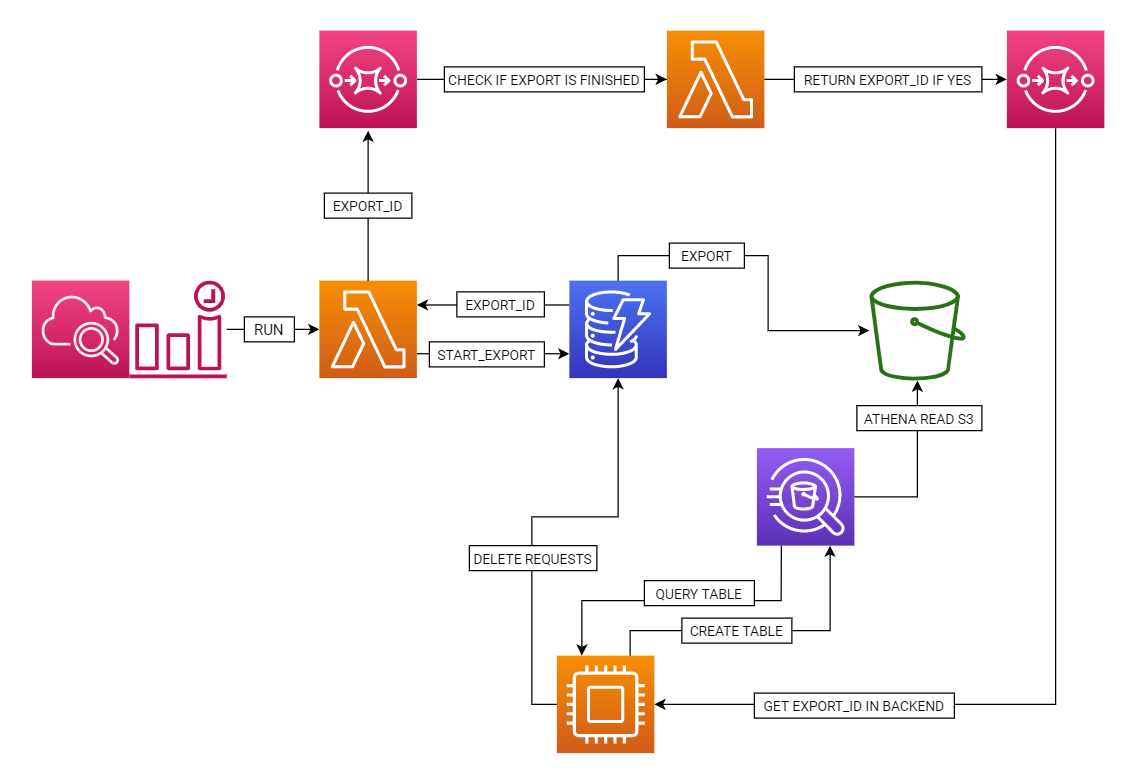
Step 1 – SQS Queues
The first thing to create are SQS queues. The one in which we will store the ID of the export that is currently in progress and it will run the lambda that will check if the export has finished. The message will come from the lambda which starts the export. The second queue will hold the ID of the export that has finished and will be served by the backend.
Step 2 – Lambda
For the export to be done automatically, we need at least one Lambda. In our case, I created two. One to initiate the export, the other to check if it has finished. This can be done in one, but for the sake of clarity I used two.
Lambda 1 – initializeExport
The lambda code is in node.js but is easily portable between different languages (Python / Java etc):

const AWS = require('aws-sdk');
const dynamoDB = new AWS.DynamoDB({
apiVersion: '2012-08-10',
maxRetries: 3,
httpOptions: {
timeout: 5000, //default 120000
connectTimeout: 5000
}
});
const sqs = new AWS.SQS({
region: 'YOUR_REGION',
maxRetries: 3,
httpOptions: {
timeout: 2000, //default 120000,
connectTimeout: 5000
}
});
var params = {
S3Bucket: 'S3_BUCKET',
TableArn: 'ARN_DYNAMODB_TABLE',
ExportFormat: 'DYNAMODB_JSON',
ExportTime: new Date,
S3SseAlgorithm: 'AES256'
}
async function sendToQueue(msg, callback) {
let sqsUrl = 'URL_TO_SQS_QUEUE'
let sqsParams = {
MessageBody: msg,
QueueUrl: sqsUrl
}
sqs.sendMessage(sqsParams,(err, data) => {
if (err) {
throw new Error(err)
} else {
callback(null, null)
}
})
}
exports.handler = (event, context, callback) => {
dynamoDB.exportTableToPointInTime(params, (err,data) => {
if (err) throw new Error(err)
else sendToQueue(JSON.stringify(data.ExportDescription.ExportArn.split("/").pop()), callback)
})
};
As you can see, lambda is very simple. What it does is first send a Request to DynamoDB with the start of the export. Then the response from this request is parsed and the export ID is extracted and sent to the SQS which is linked to the second lambda.
Lambda 2 – checkIfExportIsDone
Node.js was also used in the second lambda.

const AWS = require('aws-sdk');
const dynamoDB = new AWS.DynamoDB({
apiVersion: '2012-08-10',
maxRetries: 3,
httpOptions: {
timeout: 5000, //default 120000
connectTimeout: 5000
}
});
const sqs = new AWS.SQS({
region: 'eu-west-1',
maxRetries: 3,
httpOptions: {
timeout: 2000, //default 120000,
connectTimeout: 5000
}
});
function resendToQueue(msg, callback) {
let sqsUrl = 'YOUR_SQS_QUEUE_WHERE_LAMBDA_1_SEND_MESSAGE'
let sqsParams = {
MessageBody: msg,
QueueUrl: sqsUrl
}
sqs.sendMessage(sqsParams,(err, data) => {
if (err) {
throw new Error(err)
} else {
callback(null, null)
}
})
}
function sendToQueue(msg, callback) {
let sqsUrl = 'YOUR_SQS_QUEUE_WHERE_WE_SEND_MESSAGE_WHEN_EXPORT_IS_DONE'
let sqsParams = {
MessageBody: msg,
QueueUrl: sqsUrl
}
sqs.sendMessage(sqsParams,(err, data) => {
if (err) {
throw new Error(err)
} else {
callback(null, null)
}
})
}
exports.handler = (event, context, callback) => {
let exportId = event.Records[0].body.toString()
let exportsArray = []
dynamoDB.listExports( (err,data) => {
if (err) throw new Error(err)
else {
let exports = data.ExportSummaries
Array.from(exports).forEach((exp) => {
if (JSON.stringify(exp.ExportArn.split("/").pop().toString()) === exportId && exp.ExportStatus.toString() === 'COMPLETED') {
exportsArray.push(exportId)
}
})
if (exportsArray.length > 0) {
sendToQueue(exportsArray[0], callback)
} else {
setTimeout(() => { resendToQueue(exportId, callback) }, 60 * 1000)
}
}
})
};
The lambda is initialized by sending a message to the queue from the first lambda. The ID of the export is taken from the body of the message and then we check if the export has finished by downloading the list of all exports. If it is not finished yet – wait a minute before sending the same message to the same queue from where it came from. If it has finished, we send the message to the main queue where the message will be handled by our backend.
Step 3 – CloudWatch Event Rules
To make the export happen exactly once a day, I used the CloudWatch Event Rule setting, which fires the lambda once a day to initiate the export.
There is no code here, but a nice screenshot:

Step 4 – Handle this export in Backend (Java)
The last step is to add support for this export to our backend. We use Java as our main language and this was also the case here.
Removing the table (Athena)
String deleteTableQuery = "DROP TABLE IF EXISTS `dynamodb`.`customer_identifier`";Creating a table (Athena)
String queryString = "CREATE EXTERNAL TABLE IF NOT EXISTS `dynamodb`.`customer_identifier`(n" +
" `Item` struct<table_col_1:struct<s:string>,table_col_2:struct<s:string>,table_col_3:struct<n:integer>,table_col_4:struct<s:string>,table_col_5:struct<n:integer>,table_col_6:struct<n:integer>,table_col_7:struct<s:string>,table_col_8:struct<s:string>,table_col_9:struct<s:string>,table_col_10:struct<n:integer>,table_col_11:struct<n:integer>,table_col_12:struct<s:string>>)n"
+
" ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'n" +
" LOCATION 's3://YOUR_BUCKET/AWSDynamoDB/%s/data'n" +
" TBLPROPERTIES ('has_encrypted_data'='true')";
String tableQuery = String.format(queryString, exportId);When creating a table, we need to use struct to correctly create the table from the data exported from DynamoDB.
Getting the data
Below is a query that will extract what we need to delete data:
String queryString = "SELECT Item.table_col_1.S as partitionKey, Item.table_col_3.S as customerId FROM "DATABASE"."TABLE" WHERE Item.table_col_5.N = %d";We make a query that extracts the necessary data from the export with a whip and pulls out 1000 records at once, because there may be several thousand of them in the database and we do not want to fill up the memory.
Step 5 – Delete records from DynamoDB
Based on the data we obtained from the previous step, we only have to delete them:
public void batchDeleteItems(List<Map<String, Long>> partitionKeyAndCustomerIdMap) {
BatchWriteItemRequest batchWriteItemRequest = new BatchWriteItemRequest();
Map<String, List<WriteRequest>> requestItemsMap = new HashMap<>();
Queue<WriteRequest> writeRequests = new LinkedList<>();
partitionKeyAndCustomerIdMap.forEach(keyEntry -> {
Map.Entry<String, Long> item = keyEntry.entrySet().iterator().next();
Map<String, AttributeValue> itemPrimaryKey = new HashMap<>();
itemPrimaryKey.put(PARTITION_KEY_COLUMN_NAME, new AttributeValue(item.getKey()));
itemPrimaryKey.put(CUSTOMER_ID_COLUMN_NAME, new AttributeValue(item.getValue().toString()));
writeRequests.add(new WriteRequest(new DeleteRequest().withKey(itemPrimaryKey)));
});
while (!writeRequests.isEmpty()) {
List<WriteRequest> selectedRequests = new LinkedList<>();
for (int i = 0; i < MAX_BATCH_WRITE_ITEM_SIZE; i++) {
if (writeRequests.isEmpty()) {
break;
} else {
selectedRequests.add(writeRequests.poll());
}
}
requestItemsMap.put(TABLE_NAME, selectedRequests);
amazonDynamoDB.batchWriteItem(batchWriteItemRequest.withRequestItems(requestItemsMap));
}
}In this way, we make the most of the number of simultaneous requests to DynamoDB in the amount of 25 items removed in one request.
Important information
When creating this solution, we must not forget about IAM Role and Inline policies. Our IAM Role used by our services and with which we create an export must have the right to read data from the DynamoDB table and must be able to write data to S3.
In addition, each of the Lambda must have the appropriate permissions to perform the appropriate requests (be it to DynamoDB or read data from the SQS queue).
If something does not work, it is worth looking at the CloudWatch logs and checking what permissions are missing.
Summary
The solution seems to be complicated, but when we have billions of records in the table, using the scan () method ceases to be both efficient and profitable. The downside of this solution is that we do not have the most recent data in the export, but only the data that existed in the DynamoDB table at the time of export initialization. But due to the fact that we delete old data, it is not so important to us. The export is used as soon as it is finished and we do not use the same export anymore. If, on the other hand, you can afford to set data retention for a short period (e.g. 30 Days) and it is GDPR compliant, it will be a better solution. Of course, this solution is not limited to data deletion only. Such export can be used for faster scanning of the entire table in search of specific data.
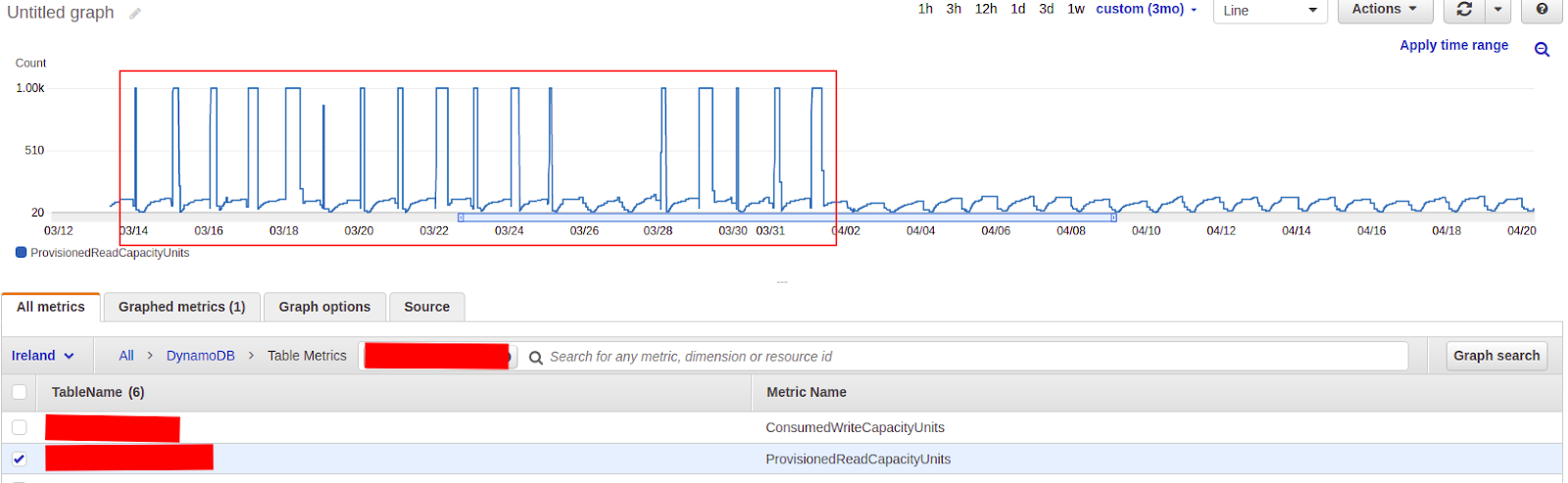
Thanks to this solution, we remained on a rigid Read / write capacity setting and we did not exceed the assumed budget for this service. This works well enough for us to move this solution to other DynamoDB tables as well.
edrone is constantly hiring! Check who we are looking for right now. If it’s you, do not hesitate and apply to our team!

Piotr Mucha
Software Engineer. Programming is not only his job but also his passion. Always happy to learn a new programming language or new technology. Winter is better than summer. Still Punk inside