
Table of contents
In the last part, we briefly described the AVA core idea. If you are still unfamiliar with it, consider starting with AVA: Our vision for the voice-based future of eCommerce, it will make this part easier to comprehend.

In the course of R&D, we quickly discovered that AVA would be something far more extensive than a chatbot.
AVA: R&D
An entire project that aims to create our own technology and allows us to develop the AVA platform and assemble Autonomous Voice Assistants.
We use a hybrid approach to address every type of customer inquiry – both exploratory and precise (know-product).
Semantics-based search works well with exploratory approach.
On the other hand, direct search requires an approach more similar to the classic one, yet nobody says that you cannot harness A.I. to it.
We mentioned earlier that “no tag or annotation can reflect a product’s nature better than an understanding of what the purpose of the search query is.” It’s not entirely true, but the problem here is different:
- It’s challenging to extract every piece of information from the query
- Products are often poorly tagged
- Products are sometimes wrongly labeled
In other words, we cannot simply ‘throw’ a list of the products into the algorithm and expect that magically will be processed into knowledge about products.
Feature Extractor
It can be called a not-that-simple information scraper. Nevertheless, the Extractor is one of AVA’s key components and, by the way, quite an exciting stand-alone feature.
We have developed a couple of algorithms dealing with traits values, names, and their annotations. First, the Extractor will automatically fetch and label the product traits and their values (sizes, colors, dimensions, features, subjective opinions, functions, etc.).
What can we use it for right now? It already returns product features and attributes from item descriptions that are not listed in, e.g., the table with technical details (table scraping is the task for the simple Extractor we developed as well, but it’s nothing exciting to talk about.) It would be a hint for product description improvement for the clients, as these traits are being interpreted as necessary from the user experience perspective – they landed in the products description, didn’t they?
gMAP and MAP – First piece of the puzzle
One of the milestones of AVA R&D is to build a machine learning model, allowing – based on natural language product descriptions and data of the products contained in structured tables – a single summary table containing all product features. We called it the gMAP algorithm, and it’s the combination of all algorithms mentioned in the previous paragraph.
Strictly speaking, the goal here is to determine what columns the master table should have, i.e., the feature names that the products in a given e-commerce should use.
Potentially we can enhance our method, using (besides descriptions) blog posts, rankings, reviews related to the product, and features of the products they carry. The sky’s the limit.We called the output structure MAP, an acronym for Mapa Atrybutów Produktów (Products’ Attributes Map). Along with gMAP (generator of MAPs), it’s truly the heart of the Platform and the essential goal of R&D labor.
Products embedding – Second piece of the puzzle
Embedding, in general, is a popular machine learning technique in which the data are encoded into a multidimensional vector space. However, it’s not a very intuitive explanation so let’s put it into simpler terms.
For example, words can be embedded in such space, and their position reflects their meaning based on their context – i.e., other words surrounding them.
Yet instead of words and context, we are using products and their features.
Product embedding allows the voice assistant to talk about products, search engine to find the best matching products, and recommendation engine to display genuinely matching products.
As I promised – it’s all related.
Tag Propagator – Third piece of the puzzle
Besides creating MAP, and dense representation of the product, we introduced the third data source to AVA’s knowledge base – good old one categories. But instead of relying on often unreliable tags, we introduced another deep learning tool in the AVA arsenal – Tag Propagator.
Propagator uses the so-called dense representation of products and clusters them, simply measuring distances between representations, then “propagating” the missing tags in the group and most of the products in the cluster already have.
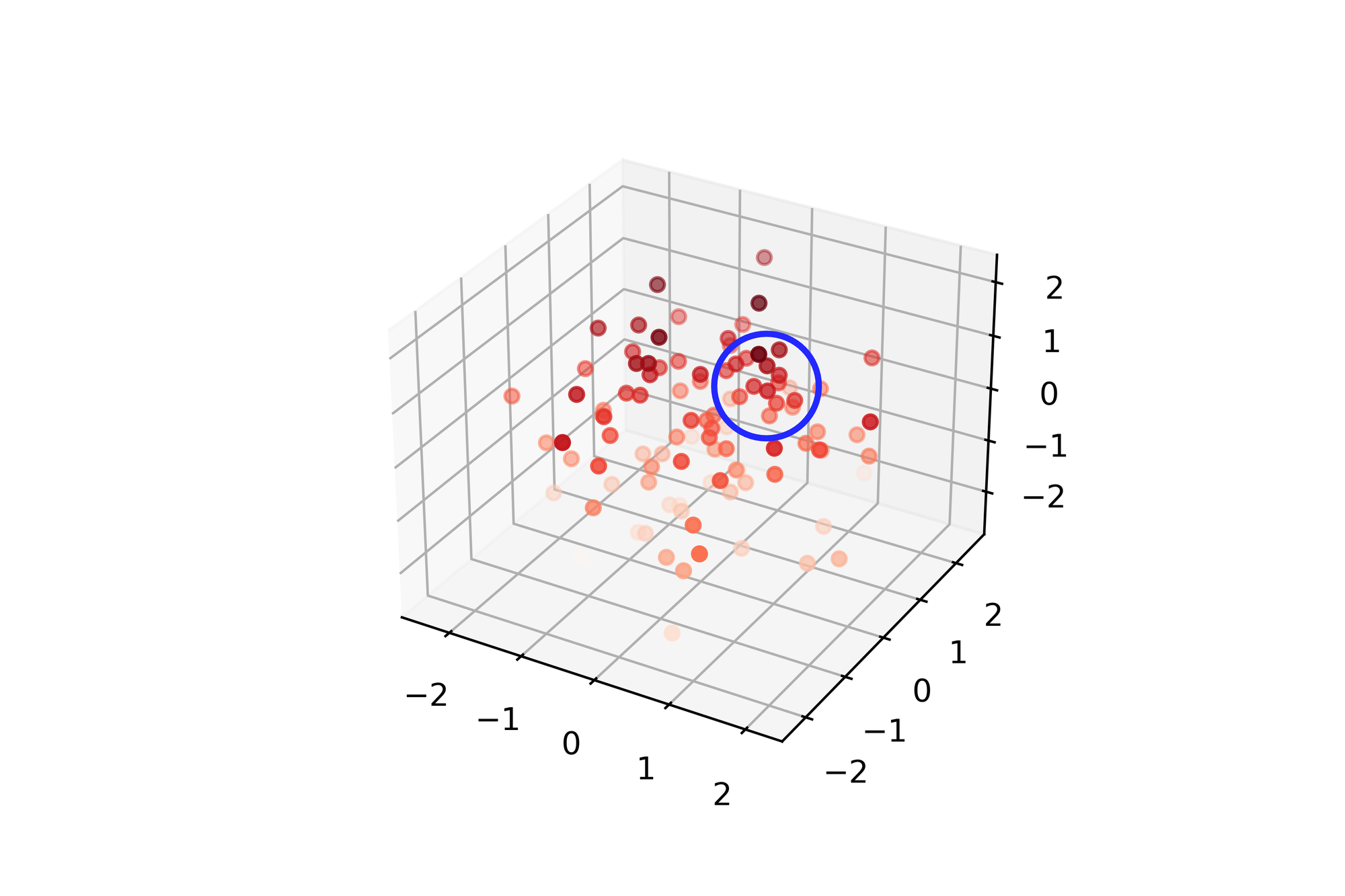
Let’s underline once again – propagator uses product description, so as long as they share some semantic aspect, they should share the same (adequate) tag.
The feature is insanely helpful regarding AVA alone, but we already found a couple of interesting tag propagator applications – SEO, for example. Let’s look at the real-life example of the Propagator mode of work.

Product Linker – The same technology, a lot of applications.
We can use dense representation in various ways. Another Application we found interesting, especially from an SEO perspective, is linking products to the adequate pieces of content in your e-store, for example – on your blog.
Product Linker is a tool helping inject related product links into any written content. The feature chops down text into paragraphs and then analyses each of them regarding matching products. Finally, Linker displays propositions in the form of pictures and links you can easily insert within your CMS.
If you are our customer, you can check and use the Product Linker now! If you want to learn more about how to use it, check the following article.
Linking the products helps your business in two ways. Both are pretty obvious; however worth underlining.
- First and foremost, clients reading and enjoying the article you wrote on your blog can instantly land on the described product. The shorter the customer path, the higher the conversion rate.
- Dense product linking significantly improves your SEO since linking, and backlinking, is one of the essential content-related SERP position factors.
Notabene: Google algorithms are based on natural language processing techniques, and so do our product linker. Thanks to that, AI de facto advertises to AI. Depending on the source, it’s called the 4th generation of marketing – M2M – Machine to machine, that ultimately will sooner or later replace, currently being on its peak, Machine to one (machine-to-one, a.k.a. segment of one).
Semantics-Based vs. Keyword Search
Let’s come back to Search! Our engine will always return a certain number of results regarding your e-commerce dynamics.
They might be less relevant in edge cases, depending on the question asked. Speaking of e-commerce recommendations (this is how we should consider search), something related is always better than nothing. At the end of the day, you sell products, not empty shelves.
AVA will increase the precision of search results and make them far more accessible than any current option.
The border between exploratory search and known-product search is fuzzy, so is our engine’s approach. Every query is processed regarding these two faces of search experience, whether using classification (decision algorithm) matching query with one type or mixing results when interpretation is inexact.
Join us on the path to a new age in e-commerce
We expect AVA to be fully operational by Q3 2023, yet there is lots to offer on the way, as you have seen. Stay tuned!

Marcin Lewek
Marketing Manager
edrone
Digital marketer and copywriter experienced and specialized in AI, design, and digital marketing itself. Science, and holistic approach enthusiast, after-hours musician, and sometimes actor. LinkedIn