
XAI: Inteligência Artificial Explicável
Índice

E-book e Planilha para Calcular KPIs do E-commerce
Use os dados da sua loja virtual a seu favor e saia na frente da concorrência!
A Inteligência Artificial já se tornou um tema corriqueiro, mencionado em notícias e presente nos produtos e serviços digitais que usamos diariamente. Mas você já parou para pensar como ela funciona? Como os algoritmos tomam suas decisões?
Estas perguntas são respondidas por uma área de estudo chamada Inteligência Artificial Explicável, também conhecida pela sigla XAI.
Gosto de me deitar no seu colo.
Entre suas pernas me enrolo.
Conheço sua casa como um mapa.
E quando caço, nenhum rato me escapa.
Qual animal esta charada descreve? Por quê?
Para nós, é muito fácil responder perguntas como esta. Porém, se passarmos esta mesma charada por um classificador de texto com uso de aprendizagem profunda (Deep Learning), a resposta provavelmente também será “gato”. Por quê? Porque o valor gerado pela função de ativação na última camada da rede neural representa a categoria “gato”. Não é muito convincente, né?
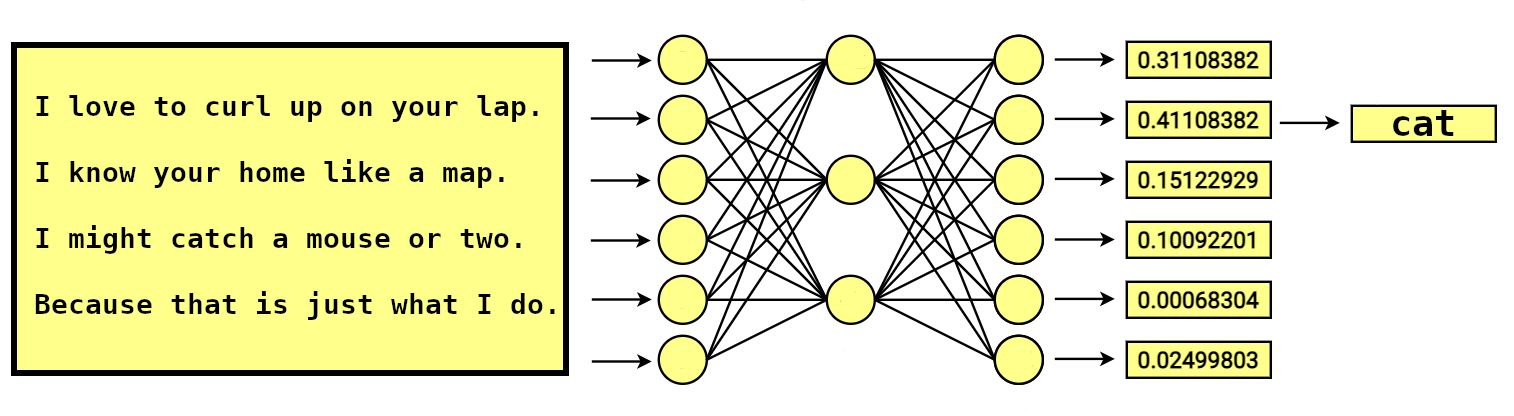
Explicação atual:
Isto é um gato.
Explicação por XAI:
Isto é um gato, pois:
- esfregar-se nas pernas dos donos é uma atividade comum entre gatos;
- gatos são animais territoriais;
- gatos caçam ratos, entre outros pequenos animais.
À medida que os modelos de Inteligência Artificial se tornam cada vez mais complexos, surgem mais perguntas sobre como determinados resultados são atingidos.
Neste artigo, apresento o conceito de Inteligência Artificial Explicável (também chamada de “interpretável”).
Introdução
A ideia de explicar o raciocínio por trás de modelos de Inteligência Artificial é um assunto que está ganhando cada vez mais popularidade. Suponho que seja porque temos usado soluções baseadas em IA cada vez mais em nossas vidas, e queremos entender como estas soluções funcionam. Isto se reflete na posição da XAI no Ciclo de Hype da Gartner sobre tecnologias emergentes.
Em 2019, a XAI entrou no pico de expectativas infladas e continua nesta seção do gráfico, o que significa que o número de pessoas interessadas neste assunto está crescendo.

Porém, vale destacar que a Inteligência Artificial Explicável não é um campo de estudo novo – é, no mínimo, tão antigo quanto os primeiros sistemas de IA. Suas origens vêm da década de 1970 e se relacionam à lógica abdutiva em sistemas especialistas (incluindo aplicações em diagnósticos médicos, projetos complexos com múltiplos componentes, e interpretações sobre o mundo real). Em seu artigo “Decision Theory Meets Explainable AI“, Karry Farming cita obras dos anos 1970 que descrevem métodos para a Inteligência Artificial Explicável, embora este termo específico não tenha sido usado.
A XAI diz respeito à Inteligência Artificial de forma ampla. Ao longo das décadas, esta área foi sendo definida por algoritmos de Aprendizado de Máquina (Machine Learning) e, mais recentemente, Aprendizado Profundo (Deep Learning), portanto os exemplos que usaremos neste artigo focarão na XAI aplicada ao Aprendizado de Máquina.
OK, já sabemos que esta não é uma ideia nova, mas que está se popularizando recentemente. Mas do que estamos falando, exatamente?
Aposte no conhecimento para desenvolver o seu negócio!
Como definir interpretabilidade?
Aqui encontramos um obstáculo, pois há um problema com a definição formal de XAI. É claro que há uma definição de interpretabilidade em lógica matemática:
Interpretabilidade é a relação entre teorias formais que expressa a possibilidade de interpretar ou traduzir uma em relação à outra.
Porém, esta definição não é útil o suficiente para nós pois é ampla demais. Felizmente, outras referências nos oferecem definições de interpretabilidade aplicada à XAI. Por exemplo:
A interpretabilidade descreve até que ponto um ser humano é capaz de entender a causa de uma decisão.
Ou então:
Estas definições são um tanto parecidas com a definição de “interpretabilidade” oferecida pelo Oxford English Dictionary (tradução livre): ‘se algo é interpretável, você pode decidir que aquilo tem um significado específico que pode ser compreendido e explicado’. Não há definição para a palavra “explicável” no Oxford English Dictionary.
Estas definições nos aproximam de nosso objetivo e nos ajudam a entender o que é XAI, porém pecam por serem difíceis de quantificar. Para os fins deste artigo, elas serão o suficiente, mas se você tiver interesse em se aprofundar nas definições, sugiro conferir o livro de Christoph Molnar. Se você também tem interesse em estudar como a interpretabilidade pode ser quantificada, recomendo este artigo científico, escrito em coautoria com funcionários da edrone.
Por que precisamos de interpretabilidade?
A resposta a esta pergunta certamente depende da nossa função e relação com a Inteligência Artificial. Pessoalmente, eu não me sinto confortável com o fato de que cada vez mais modelos são “caixas pretas”. Em outras palavras, nos apoiamos em modelos que têm estruturas complexas e são de difícil compreensão para seres humanos.
É claro, a capacidade de entender modelos complexos varia de pessoa para pessoa. Isso depende muito do nível de conhecimento técnico que a pessoa tem, e é impossível definir claramente o limite (por exemplo, o número de parâmetros de um modelo) em que a compreensão de um modelo excede as capacidades cognitivas de uma pessoa.
Comparados às máquinas, os humanos também são limitados em sua capacidade de compreender relações multidimensionais. De acordo com o psicólogo George Miller, as pessoas são capazes de armazenar em suas memórias de curto prazo, em média, 7 ± 2 elementos. Portanto, para poder ser compreendido por um ser humano, um modelo precisa ter um pequeno número de parâmetros ou variáveis.
Na prática, de acordo com Biecek and Burzykowski, este limite está mais próximo de 10 parâmetros do que de 100 para a maioria das pessoas – e essa variação depende de se tratar de uma pessoa leiga no assunto ou um especialista em Aprendizado de Máquina que já está acostumado a analisar algoritmos. De qualquer forma, estes números são minúsculos quando comparados ao tamanho de redes neurais modernas – por exemplo, a versão completa do GPT-3 tem capacidade para 175 bilhões de parâmetros de Aprendizado de Máquina.
A pergunta que fica, então, é: por que não usamos apenas modelos interpretáveis?
A resposta é simples: por causa da correlação entre a complexidade do modelo e sua qualidade. Em poucas palavras, os modelos que somos capazes de interpretar fornecem resultados muito piores do que as “caixas pretas”. Isso é ilustrado no gráfico abaixo.
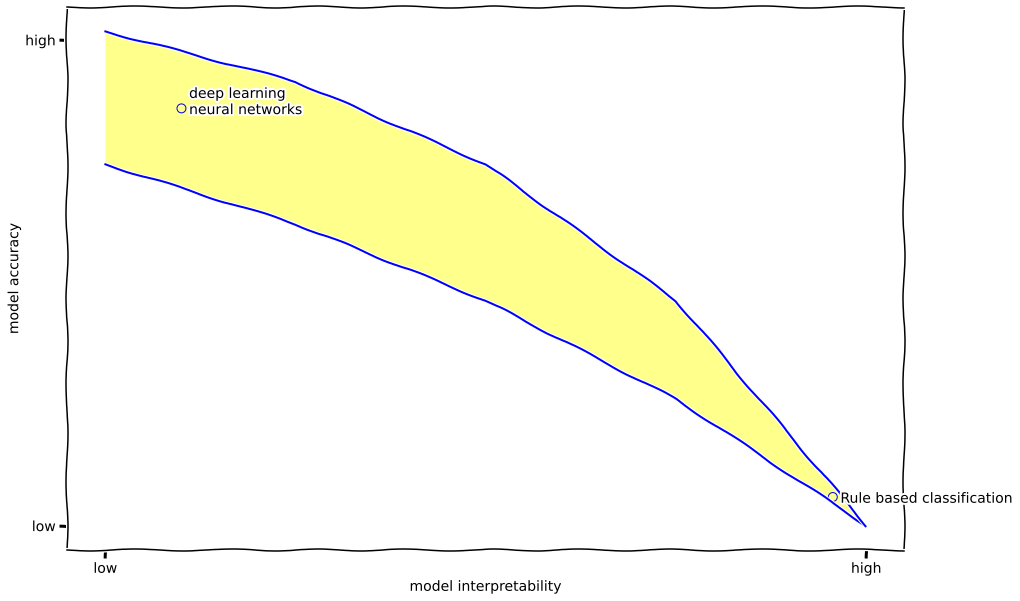
Voltando à pergunta acima, a interpretabilidade também é necessária por outras razões. Por exemplo, confira um dos resultados da 22nd Annual Global CEO Survey, uma pesquisa conduzida pela PwC junto a 1.378 CEOs espalhados pelo mundo.
A grande maioria dos CEOs (84%) ‘concorda’ que decisões embasadas em IA precisam ser explicáveis para que sejam confiáveis. Isso é mais do que os que concordam com a afirmação de que a IA é boa para a sociedade (79%). Abrir a “caixa preta” dos algoritmos de IA é fundamental para a sua difusão à medida que aumentam sua complexidade e o impacto de suas decisões (p. ex. diagnósticos médicos, veículos autônomos).
Vamos tentar apontar alguns dos motivos mais importantes para lidarmos com este assunto:
- Segurança. Modelos de Aprendizado de Máquina executam tarefas do mundo real. Por exemplo, eles auxiliam em diagnósticos médicos, dirigem veículos autônomos, embasam decisões jurídicas e dão suporte a investigações policiais, entre outras. Isso tudo exige que testes e medidas de segurança sejam tomadas para garantir que estes modelos sejam seguros para a sociedade, e entender estes modelos é fundamental para assegurar que sejam seguros. Em outras palavras, os modelos de Aprendizado de Máquina só podem ser auditados quando são interpretáveis.
- Regulamentação. Você provavelmente já ouviu falar na Lei Geral de Proteção de Dados (LGPD) brasileira ou na GDPR europeia. Estas leis prevêem o direito à explicação, ou seja, o direito de receber uma explicação pela decisão tomada por um sistema automatizado. Em 2016, antes da GDPR, a França já havia promulgado a “Lei por uma República Digital”, ou Loi Numérique, que introduziu a exigência de que os órgãos públicos deveriam fornecer explicações sobre decisões tomadas a respeito de indivíduos. Regulamentações semelhantes foram implementadas a respeito de “scores de crédito” nos EUA, de modo que hoje os credores são obrigados a notificar as pessoas que tiveram seus pedidos de crédito negados, fornecendo explicações sobre a decisão. Ou seja, ao desenvolver soluções de Inteligência Artificial, devemos ter em mente as regulamentações vigentes no país onde o algoritmo será usado, pois elas podem exigir que ele seja interpretável.
- Depuração. A interpretabilidade também é uma ferramenta muito útil para o desenvolvimento de soluções de IA, pois se torna mais fácil encontrar potenciais falhas no código ou componentes específicos que estejam prejudicando o desempenho do sistema. Se o modelo estiver refletindo um viés presente nos dados de treinamento, técnicas de XAI podem facilitar sua identificação e correção.
- Aceitação social. O Jornal Oficial da União Europeia (2017/C 288/01) inclui este trecho: “A aceitação e o desenvolvimento e a aplicação sustentáveis da IA dependem da possibilidade de compreender, verificar e explicar o funcionamento, as ações e as decisões dos sistemas de IA, sobretudo também a posteriori.“ Isto resume muito bem os critérios que devem ser cumpridos para que o público em geral aceite o desenvolvimento da Inteligência Artificial. Isto é muito importante porque algumas pessoas têm medo da Inteligência Artificial, o que é evidenciado pelas discussões negativas sobre o assunto que se acaloraram recentemente. Você pode aprender mais sobre a aceitação social da IA no artigo (em inglês) Building Trust to AI Systems Through Explainability. Technical and Legal Perspectives, escrito em coautoria com membros da equipe AVA.
- Curiosidade humana. O ser humano tem uma vontade inerente de conhecer o mundo ao seu redor, portanto a curiosidade humana e o nosso desejo pelo conhecimento também são importantes razões para desenvolver a XAI.
É claro que não devemos sempre colocar o critério de interpretabilidade nos modelos como condição imprescindível. Não é importante compreender profundamente os modelos que não têm impactos significativos – por exemplo, os que estão em Tamagotchis ou Hot Wheels. Em geral, devemos nos apoiar em nosso senso de ética ao responder a pergunta: a interpretabilidade é importante para este modelo?
Também vale lembrar que uma alternativa à exigência legal ou ética pelo uso de Inteligência Artificial Explicável pode ser a ideia de “envelopamento” proposta por Robbins. Robbins argumenta que modelos de IA operando em espaços bem definidos (“envelopados” em microambientes físicos e virtuais que permitem que os modelos sirvam seu propósito enquanto evitam qualquer dano aos seres humanos) não precisariam ser explicáveis porque seu escopo e mecanismos de operação garantiriam confiança mesmo que os detalhes de suas decisões não sejam totalmente transparentes.
É claro, nem sempre é viável criar um ambiente de desenvolvimento como este, então a ideia de Robbins não substitui a XAI, mas sim a complementa.
Prós e contras
Até aqui, este artigo apresentou apenas as vantagens da XAI – e de fato são muitas. Vamos recapitular algumas das que já vimos, e incluir algumas outras:
- Mais confiança e segurança nos resultados fornecidos pelo modelo;
- Adoção mais ampla dos modelos atualmente em produção, pois eles fornecerão explicações das previsões às partes envolvidas;
- Ajudam na depuração para identificar viés nos dados;
- Conformidade a leis de proteção de dados;
- A XAI facilita a Democratização da Inteligência Artificial
- A XAI é um passo rumo à Inteligência Artificial Responsável
No entanto, é importante destacar que a XAI não é uma panaceia e, além do devido reconhecimento, também há críticas válidas. Eis algumas delas:
- A XAI é, no melhor dos casos, desnecessária, e no pior dos casos, danosa. Além disso, ela ameaça impedir a inovação;
- A XAI favorece decisões humanas em detrimento das decisões tomadas pelos algoritmos;
- A XAI foca nos processos em detrimento dos resultados;
- As decisões humanas muitas vezes não são facilmente explicáveis, pois podem se basear em intuições difíceis de expressar em palavras. Por que as máquinas deveriam atingir um padrão mais exigente que o dos seres humanos?;
- Alguns algoritmos parecem ser inerentemente difíceis de explicar;
- Não há uma definição matemática da interpretabilidade de modelos de Inteligência Artificial, o que dificulta a medição do “grau de interpretabilidade”;
- Os modelos explicativos são, eles mesmos, “caixas pretas”;
- A interpretabilidade pode permitir que pessoas ou programas manipulem o sistema.
Vale a pena assistir a um debate interessante que aconteceu há alguns anos atrás na Universidade de Oxford entre grandes nomes do Aprendizado de Máquina: The Great AI Debate – NIPS2017 – Yann LeCun (em inglês). Neste vídeo, você encontrará argumentos de ambos os lados, favoráveis e contrários à interpretabilidade, embasados por exemplos interessantes.
Métodos de XAI
A XAI pode ser incorporada desde o início em um algoritmo de Aprendizado de Máquina, ou pode ser uma aplicação independente do modelo (via um método externo, modelo-agnóstico ou modelos substitutos).
O primeiro tipo diz respeito aos modelos “caixa branca” ou “caixa de vidro”. Apenas algoritmos simples de Aprendizado de Máquina (modelos de regressão, modelos lineares generalizados, árvores de decisão) permitem que seus resultados sejam interentemente explicáveis dentro do modelo.
O contrário é verdadeiro para os modelos “caixa preta”, como os de Aprendizado Profundo (Deep Learning).
No caso dos modelos “caixa preta”, a XAI se apoia em métodos modelo-agnósticos (não específicos para um determinado algoritmo). A interpretação analisa apenas os dados de entrada (input) e de saída (output), e não o que está acontecendo internamente no algoritmo. Outros modelos de Aprendizado de Máquina resumem ou aproximam os resultados do algoritmo, mas ao mesmo tempo são muito mais simples de interpretar (é o modelo da “caixa de vidro”). Nesta categoria, temos explicações amplas, que mostram as tendências gerais das influências das variáveis sobre a pontuação do modelo de Aprendizado de Máquina – por exemplo, elas podem mostrar que uma renda 10% maior se traduzirá em um aumento médio de 5% na probabilidade de se conseguir crédito. O modelo mais flexível é o das chamadas explicações locais, que fornecem explicações para observações específicas. Por exemplo, este modelo pode fornecer uma explicação de por que uma pessoa específica não foi aprovada para receber um empréstimo.
Segue abaixo uma lista (incompleta) de métodos usados para explicar modelos.
Métodos modelo-agnósticos:
- Métodos que resumem o efeito de variáveis específicas nos resultados de um algoritmo, como se estivessem isoladas das demais variáveis:
— Partial Dependence Plot (PDP), ou ceteris paribus
— Individual Conditional Expectation (ICE)
— Gráfico Accumulated Local Effects (ALE) - Método semelhante aos anteriores mas que, além disso, ilustra o efeito combinado de múltiplas variáveis:
— Feature Interaction - Método que se baseia na suposição de que as variáveis que não são importantes para o resultado fornecido pelo modelo de Aprendizado de Máquina – de acordo com a XAI – podem ser alteradas aleatoriamente, em pequena escala, sem ter grandes impactos no resultado:
— Permutation Feature Importance - Métodos que encontram uma aproximação do modelo que está sendo interpretado, seja em nível global (uma explicação para o modelo inteiro) ou local (uma explicação distinta para cada observação):
— Global Surrogate
— Local Surrogate (LIME) *
— Scoped Rules (Anchors) - Métodos que, usando uma abordagem derivada da Teoria dos Jogos, descrevem a influência (contribuição) de variáveis individuais no resultado do algoritmo sendo interpretado, no nível das observações individuais – ou, em alguns casos, fornecendo interpretações globais.
— Shapley Values
— SHAP (SHapley Additive exPlanations)
* Nós focamos no método LIME para Processamento de Linguagem Natural em um webinar recente. Se você tiver interesse na matemática por trás deste método, ou quiser conferir alguns exemplos de uso ao vivo, acesse abaixo a gravação (em inglês):
Explicações baseadas em exemplos
- Explicações contrafatuais nos dizem como uma instância precisa mudar significativamente para mudar sua previsão. Ao criar instâncias contrafatuais, aprendemos como o modelo faz suas previsões e assim podemos explicá-las individualmente. Um exemplo deste tipo de explicação: Você receberia um empréstimo se a sua renda fosse 5% mais alta ou se você aumentasse o valor das suas parcelas atuais em R$ 200 a mais por mês.
- Exemplos adversários são argumentos contrafatuais usados para enganar modelos de Aprendizado de Máquina. Aqui o ênfase é em inverter a previsão, e não explicá-la.
- Protótipos são uma seleção de instâncias representativas dos dados, e críticas são as instâncias que não são bem representadas pelos protótipos.
- Instâncias influentes são os dados de treinamento que foram mais influentes para os parâmetros de um modelo de previsão, ou para as previsões em si. Identificar e analisar instâncias influentes ajuda a encontrar problemas nos dados, depurar o modelo e entender melhor o seu comportamento.
- Modelo k-vizinhos mais próximos: um modelo interpretável de Aprendizado de Máquina baseado em exemplos.
Interpretação de redes neurais
- Visualização de recursos (quais recursos, ou features, a rede neural aprendeu?)
- Conceitos (Quais conceitos mais abstratos a rede neural aprendeu?)
- Atribuição de recursos (Como cada input contribuiu para uma previsão específica?)
- Destilação de conhecimento (Como podemos explicar uma rede neural usando um modelo mais simples?)
Para entender mais sobre o assunto, recomendo estes dois livros (em inglês):
Se você tiver interesse em acessar uma lista mais extensa de referências científicas, confira o Apêndice A do artigo “Explainable Artificial Intelligence: a Systematic Review” (em inglês).
XAI na edrone
Finalmente, gostaria compartilhar brevemente nossa abordagem sobre Inteligência Artificial Explicável. Na edrone, estamos desenvolvendo a AVA, um Assistente Virtual Autônomo para E-Commerce. Esta é uma solução que usa Inteligência Artificial para melhorar a experiência do usuário trabalhando junto com ferramentas de automação de marketing para e-commerce, e nós nos preocupamos com a interpretabilidade porque acreditamos que isso nos ajudará a construir um produto melhor.
Quer aumentar as suas vendas e construir um relacionamento com os seus clientes?
Como mencionei ao longo deste artigo, a XAI nos ajuda a depurar nossos modelos, facilita as conversas com potenciais clientes, entre outras coisas. Também promovemos seminários in-house para discutir assuntos relacionados à XAI – mostrando um pouco as cartas aqui, este artigo se baseou em um destes seminários – e estamos trabalhando em parceria com instituições acadêmicas para desenvolver o conhecimento científico sobre XAI – você encontra aqui o nosso artigo mais recente.
Continuaremos falando sobre XAI aqui em nosso blog no futuro, então fique de olho 🙂

Pedro Paranhos
Margeting manager
edrone
Gerente de Marketing LATAM na edrone. Profissional de marketing full-stack interessado em tecnologia, história (passado e futuro), negócios e idiomas. Leitor de livros e entusiasta de cervejas artesanais.
E-book e Planilha para Calcular KPIs do E-commerce
Use os dados da sua loja virtual a seu favor e saia na frente da concorrência!


